论文阅读笔记
深度学习论文阅读笔记
跟着 mli/paper-reading: 深度学习经典、新论文逐段精 这个系列视频进行学习,这里做一个简单的笔记
如何读论文
https://www.bilibili.com/video/BV1H44y1t75x/
这个收获比较大的地方是第一次看论文的abstract和conclusion
第二次看图表
AlexNet
https://www.bilibili.com/video/BV1ih411J7Kz
深度和宽度都重要
AlexNet之前人们认为无监督学习更好,AlexNet证明了数据量够好和够深的网络也能打赢无监督学习
预处理:简单裁剪
end to end
并行训练:现在NLP领域又兴起了
dropout在现行模型上等价于一个L2正则项
降lr的方法:人工手工降(现在用cos函数慢慢降低
ResNet
https://www.bilibili.com/video/BV1Fb4y1h73E
可以用ResNet来让更深的模型更容易训练
和AlexNet一样的降lr方法
ResNet训练比较快的原因:梯度保持的好
Transformer
https://www.bilibili.com/video/BV1pu411o7BE
编码器-解码器架构,解决机器翻译问题
RNN 特点(缺点):难以并行,丢失很早的历史信息
encoder 一次性看全整个句子,decoder 的输出词是一个一个生成的
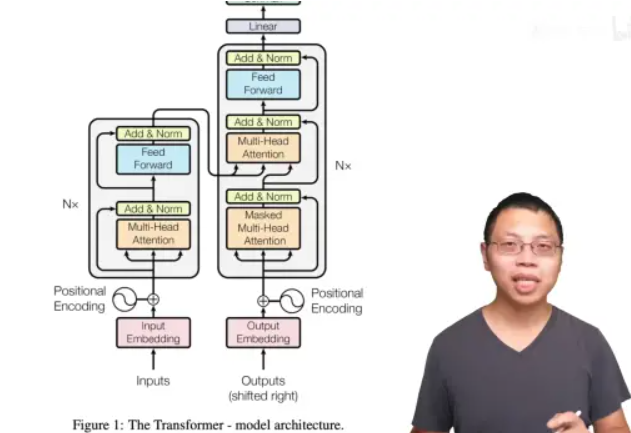
简单设计:只需调 2 个参数 dmodel 每层维度有多大 和 N 多少层,影响后续一系列网络的设计,BERT、GPT。
LayerNorm而不是BatchNorm
做Mask的方法:把 t 时刻以后 Qt 和 Kt 的值换成一个很大的负数
Positional Encoding:简单相加
GNN
https://www.bilibili.com/video/BV1iT4y1d7zP/
图信息:点,边,图整体(虚构,来连接很远的点),连接情况
问题:矩阵很大(难以存储),边通常是稀疏的(难以并行),邻接矩阵的 行、列顺序交换,不会影响图(异构)
方法:存一个邻接列表
可以做几个MLP来研究4种图信息的关系,可以分开做,也可以一起做(GCN)
GNN 对超参数比较敏感
GAN
https://www.bilibili.com/video/BV1rb4y187vD
每次迭代,先更新 D 再更新 G,但是双方最好实力相当
无监督学习,无需标注数据
BERT
https://www.bilibili.com/video/BV1PL411M7eQ
pre-training: 在一个大的数据集上训练好一个模型 pre-training,模型的主要任务是用在其它任务 training 上。
BERT: 用深的、双向的、transformer 来做预训练,用来做语言理解的任务。
GPT unidirectional,使用左边的上下文信息 预测未来
NLP任务分两类:句子关系,完形填空
BERT 通过 MLM 带掩码的语言模型 作为预训练的目标,来减轻 语言模型的单向约束。
在无标号的大量数据集上训练的模型效果 > 有标号、但数据量少一些的数据集上训练效果不好
在大量无标号的图片上训练的模型,可能比 有标号的 ImageNet 百万图片 效果更好。
ViT
https://www.bilibili.com/video/BV15P4y137jb
原本cv中的注意力:attention + CNN ,轴attention
对图片块进行自注意力
CNN的归纳偏置:先卷积还是先平移没有影响
CNN 有 很多先验信息 –> 需要较少的数据去学好一个模型
引入一维位置编码
InstructGPT
感觉比较有意思的地方是用了强化学习,专门做了一个RL模型(奖励)来给原来模型的微调模型(策略)给分,因为微调参数变了,分布参数也会变。然后RL是个排序模型,可以节省大量的标注。
GPT-1-2-3
Bert是完形填空,GPT是预测未来(更难但是上限更高)
GPT是预训练模型,是Transformer的解码器。(BERT:编码器)
GPT在训练过程中加入了分隔符这种辅助的符号
GPT2主打zero-shot,相对没特别多的创新
GPT3是few-shot,训练完了不更新模型参数
多模态
https://www.bilibili.com/video/BV1Vd4y1v77v/
https://blog.csdn.net/qq_42030496/article/details/136051417
多模态看来真的很吃资源
CLIP:使用对比学习,将不相关的图像和文本之间的距离拉大,相关的图像和文本之间的距离拉小,最后只要做一个点乘就好了
ALBEF
在多模态学习中,视觉特征编码器要大于文本特征编码器,引入ITC loss
ITM loss:
那我们就先来说一下这个 ITM loss,也就是 image text matching,其实很简单,就是说你给定一个图片,给定一个文本,而这个图像文本通过这个 ALBEF的模型之后,就会出来一个特征,那在这个特征之后加一个分类头,也就是一个 FC 层。然后我去判断到底这个 i 和 t 是不是一个对,那说白了这个 ITM 就是一个二分类任务。那这个 loss 虽然听起来很合理,我们确实应该用它,但是实际操作的时候你会发现这个 loss 太简单了。因为判断正样本可能还有点难度,但是判断谁和谁是负样本,这个就太简单了。因为如果你不对这个负样本做什么要求,那基本上很多很多的这个图片/文本,它都可以当成是现在图像/文本内的负样本,所以这个分类任务很快它的准确度就提升了很高很高。那在预训练的时候,训练再久其实也没有任何意义了。那这个时候一个常见的做法,就是说我在选这个负样本的时候,我给它一些constrain。那在 ALBEF这篇论文里,它就是采取了最常用的一个方法,就是通过某种方式去选择最难的那个负样本,也就是最接近于正样本的那个负样本。具体来说。那在 ALBEF这篇论文里,它的这个 batch size 是512,那对于 ITM 这个 loss 来说,它的这个正样本对就是 512 个。那对于这个 Mini batch 里的每一张图像,我去哪儿找它的这个 hard negative 的文本,这个时候 ITM 还依赖于之前的这个ITC,他就把这张图片和同一个 batch 里所有的这个文本都算一遍这个 cosine similarity,然后他在这里选择一个除了他自己之外相似度最高的那个文本当做这个negative。也就是说其实这个文本和这个图像已经非常相似了,它基本都可以拿来当正样本用,但是我非说它是一个负样本,也就是 hard negative 的定义。那这个时候 ITM loss 就变得非常 challenging 了,然后让这个模型更好的去判断谁到底是一个图像文本对,也就是他这里说的 image text matching。
MLM loss
那最后一个目标函数就是我们耳熟能详的 mask language modeling Bert 里用的完形填空,那其实就是把原来完整的句子这个 text t 变成一个 t’,也就是说有些单词被musk 掉。然后他把这个缺失的句子和这个图片一起,通过这个 ALBEF的模型,然后最后去把之前的这个完整的句子给预测出来。那在这里其实它不是像 NLP 那边单纯的一个 MLM 了,它其实也借助了图像这边的信息去帮助它更好的恢复这个哪个单词被 mask 掉。
但这里有一个小细节很值得关注,就是说在我们算这个 i t c loss 和这个 i t m loss 的时候,其实我们的输入都是原始的 i 和t,但是当我们算这个 m l m loss 的时候,它的输入是原始的i,但是mask过 的t。这意味着什么呢?这说明 ALBEF这个模型每一个训练的iteration,其实它做了两次模型的forward。一次模型的forward 是用了这个原始的 i 和t,另一次模型的 forward 是用了原始的 i 和mask过 的t。当然了,不光是 ALBEF这篇论文会有这种多次前向的这个过程,其实 vilt 包括之前的很多模型,它都会做好几次前向,甚至做三次前向过程。这也是其中一个原因。就是**为什么多模态学习普遍的方法,它的训练时间都比较长,**因为它为了算好几个不同的loss,它还得做好几次不同的 forward 去满足各种各样的条件。****那到这儿三点儿一和三点儿 2 节就讲完了,最后我们可以看到在文章的这个公式5,这个 ALBEF的所有在训练时候用的这个目标函数就都在这里了,就是 ITC MLM 和 ITM 的这个合体。
动量蒸馏:将独热标签变成多热标签,算Softmax score,可以利于在noise中学习
VLMo
将两个模态分开训练,看下图,transformer的参数共享,但是最后不同模态的FFN层不同,在执行不同任务时使用不同的结构
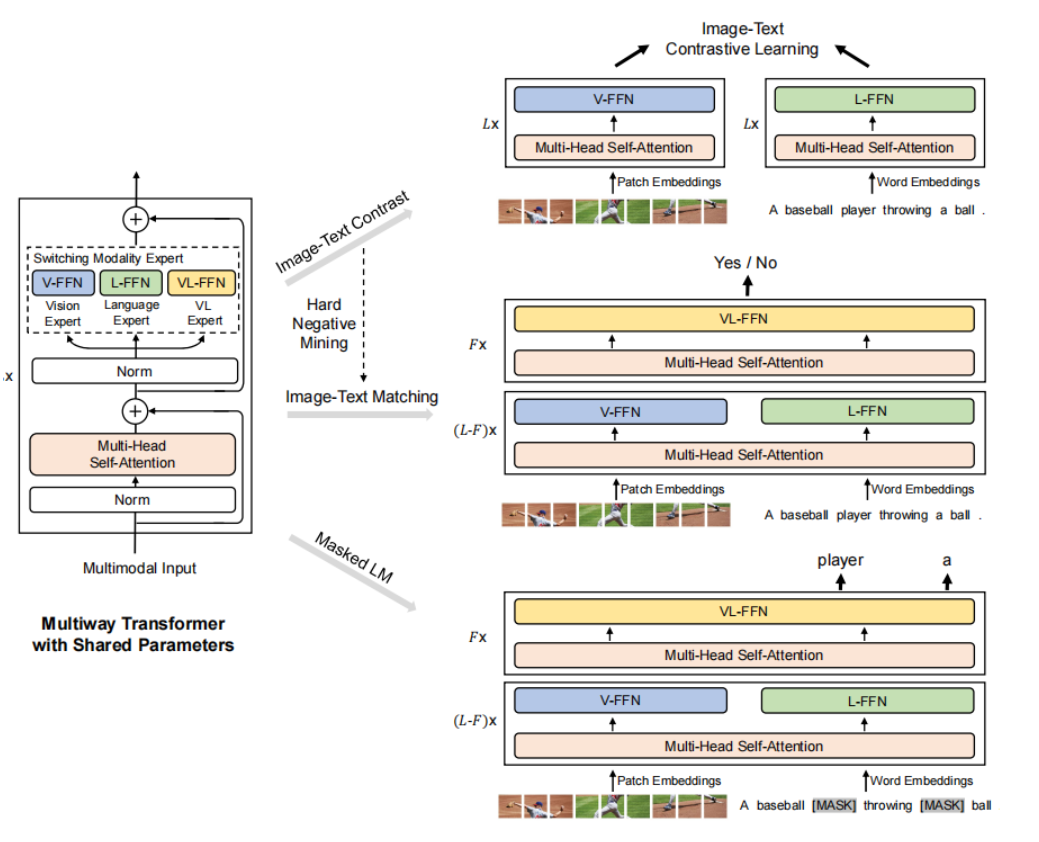
这个训练顺序还挺有意思的:
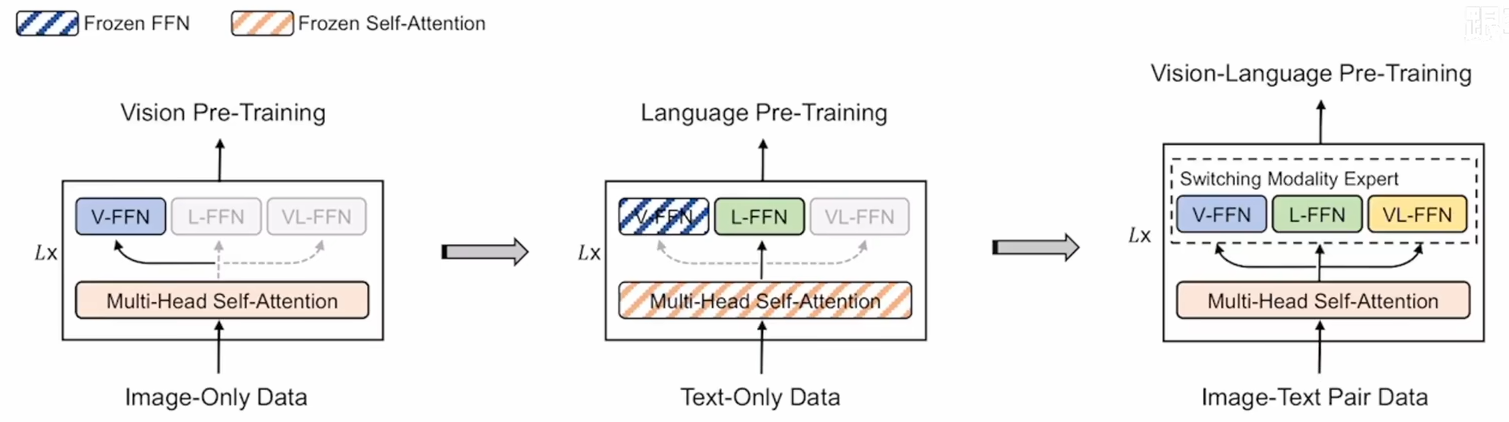
注意第二步:拿视觉上训练好的自注意力层参数去建模文本
Neural Corpus Indexer
文档检索是一件很贵的事(因为文档可能很多)
输入查询,输出id,但是我们的数据是<doc和doc-id>,可以将doc拆成很多查询
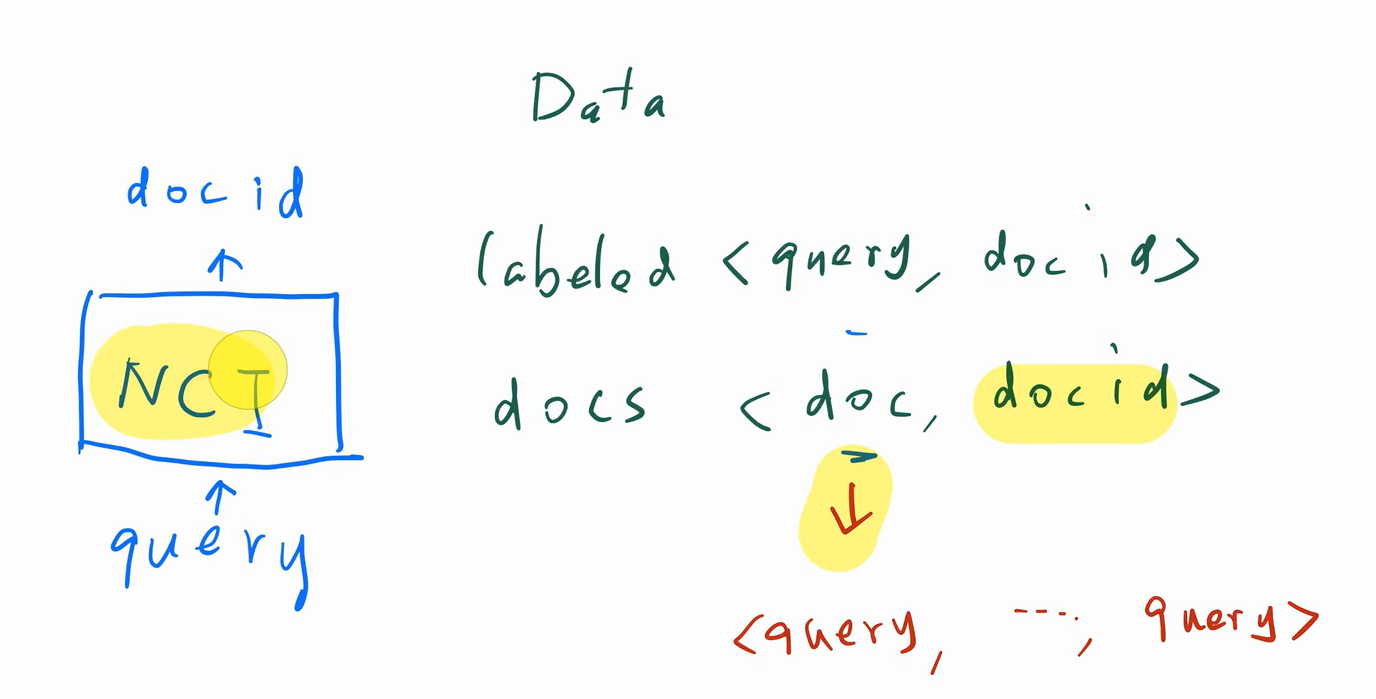
层次化K-means
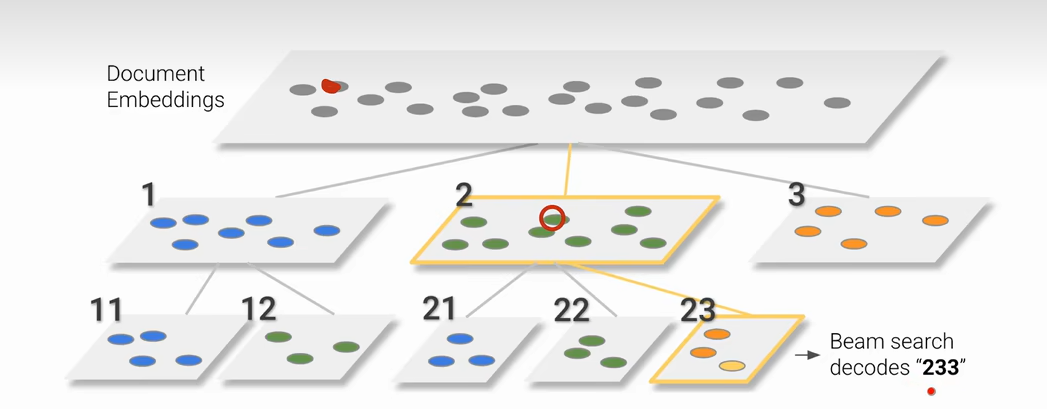
得到的decodes前缀类似说明这两个类比较接近
Parameter Server
沐神自己的论文,系统+ai方向,是比较有机的融合而不是简单的a+b
www.bilibili.com/video/BV1YA4y197G8
和分布式有关,写了一段给不搞机器学习的学者看的机器学习科普
OpenAI Whisper
www.bilibili.com/video/BV1VG4y1t74x/
数据集足够大,模型的选择关系不是很大,效果都差不多
它的输入是一个时间为横坐标,频率为纵坐标的数据结构(值为能量)
弱监督学习:弱监督学习中,训练样本的标签可能是不可靠的,这包括标签不正确、多种标记、标记不充分或局部标记等情况。与强监督学习相比,弱监督学习中的标签可能并不总是准确地表示样本的真实类别或属性。
弱监督学习(Weakly Supervised Learning)是一种机器学习范式,它介于完全监督学习和完全无监督学习之间。在这种学习方式中,模型使用的标签信息是部分正确、不完整或不确定的。弱监督学习通常用于以下情况:
- 标签噪声:训练数据的标签可能包含错误或不一致性。
- 标签不完整:只有部分数据有标签,其他数据没有标签。
- 标签模糊:标签可能不够精确,例如,对于图像分类任务,标签可能只是“动物”,而不是具体的“猫”或“狗”。
- 标签成本高:获取精确标签的成本很高,因此只能提供低成本的、质量较低的标签。
弱监督学习的目标是利用这些不完美的标签来训练模型,同时尽可能地减少标签错误对学习过程的影响。这通常涉及到一些特殊的算法或技术,例如:
- 数据清洗:在训练前尝试识别和纠正标签中的错误。
- 集成学习:结合多个模型的预测来提高整体的准确性。
- 主动学习:模型主动选择最不确定的样本请求标注,以减少对不准确标签的依赖。
- 多任务学习:同时学习多个相关任务,以利用任务之间的相关性来提高学习效果。
弱监督学习在实际应用中非常有价值,因为在很多情况下获取大量精确标注的数据是不现实的。通过弱监督学习,可以更有效地利用现有的数据资源,提高模型的泛化能力和实用性。
自监督学习:
自监督学习是一种从无标签数据中挖掘监督信息,以训练机器学习模型的方法。
在机器学习领域,自监督学习是介于监督学习和无监督学习之间的一种范式。它利用辅助任务(或称为假托任务)从未标记的数据中生成隐式标签,以此来训练模型。这种方法的核心在于,通过构造某种形式的监督信息,使模型能够在没有人工标注的情况下进行训练。这种学习方式在计算机视觉和自然语言处理等领域尤为有用,因为这些领域通常需要大量标注数据来训练先进的AI模型,而获取这些标注数据既耗时又昂贵。
自监督学习的主要方法可以分为基于上下文、基于时序和基于对比三种类别。例如,在NLP领域中,Word2vec算法通过预测句子中词的顺序来学习单词的表征,而在图像处理中,研究人员通过调整图像块的位置并让模型预测其相对位置来学习图像的特征。这些方法都旨在通过自动构建的预测任务来学习数据的有用表征,从而对下游任务产生积极影响。
自监督学习的发展不仅解决了监督学习依赖手工标注数据的问题,还为模型提供了更丰富的语义表征。这种学习方式使得模型能够在没有明确人工标注的情况下,通过数据本身的内在结构和相关性获得有效信息。因此,自监督学习在减少人工标注成本和提升模型泛化能力方面具有显著优势。
总的来说,自监督学习通过创新地从数据自身提取监督信号,实现了在无需外部标注的情况下训练高效机器学习模型的目标。这一方法不仅节省了数据标注的成本和时间,还在某些情况下提高了模型的泛化能力和性能表现,成为人工智能领域的重要研究方向。
自监督和无监督学习有什么区别?
自监督学习和无监督学习在机器学习中都是重要的概念,它们之间的区别主要体现在以下几个方面:
- 学习目标和方式
- 自监督学习:自监督学习可以看作是特殊的无监督学习的一个子类别,但它并非完全等同于无监督学习。自监督学习的关键思想是让模型无需手动标签即可学习数据表示。在自监督学习中,模型会利用输入数据的某些特性,自动生成目标标签,最终通过这些标签来训练模型。例如,模型可能会假设图像中相邻的像素存在相互关系,或者音频信号中连续的时间片段具有类似的特征等。
- 无监督学习:无监督学习则是在没有明确标签或指令的情况下,根据数据本身的潜在关联,从数据集中提取特征、模式和关系的机器学习方法。它的主要目的是通过模型的自学习期来发掘数据的内在结构和模式,更好地理解数据背后的潜在规律,并将其扩展到新的情境中。
- 目标函数的选择
- 自监督学习:在自监督学习中,模型会自动生成目标标签,并在这些自动生成的目标上进行学习。常见的自监督学习算法包括自动编码器(Autoencoder)和对比性预训练(Contrastive Pretraining)等。
- 无监督学习:无监督学习则是在数据集的自然结构上学习,而不是在自动生成的目标上。无监督学习的方法包括聚类、异常检测、数据降维等。
半监督学习:
半监督学习(Semi-supervised learning)是一种机器学习方法,它利用少量标记数据和大量未标记数据来训练模型。与监督学习和无监督学习相比,半监督学习具有以下特点:
- 利用了标记数据和未标记数据的优势:标记数据可以为模型提供学习方向,而未标记数据可以丰富模型的训练集,提高模型的泛化能力。
- 降低了对标记数据的需求:在许多实际应用中,标记数据的获取成本很高,而未标记数据的获取成本相对较低。因此,半监督学习可以帮助我们降低对标记数据的需求。
- 提高了模型的性能:在许多情况下,半监督学习可以比监督学习和无监督学习取得更高的性能。
半监督学习的工作原理可以概括如下:
- 收集大量未标记数据和少量标记数据。
- 利用标记数据训练一个初始模型。
- 使用初始模型对未标记数据进行预测,并根据预测结果为未标记数据分配伪标签。
- 将伪标签数据与原始标记数据一起用于训练最终模型。
半监督学习的常见算法包括:
- 自我训练(Self-training):这是最简单的半监督学习算法之一。它使用初始模型对未标记数据进行预测,并根据预测结果为未标记数据分配伪标签。然后,将伪标签数据与原始标记数据一起用于训练最终模型。
- 期望最大化(Expectation-maximization,EM):EM算法是一种迭代算法,它通过交替估计模型参数和隐变量来最大化模型的似然函数。在半监督学习中,EM算法可以用于估计模型参数和未标记数据的伪标签。
- 图半监督学习(Graph semi-supervised learning):图半监督学习利用图结构来辅助半监督学习。在图半监督学习中,未标记数据之间的关系可以用图来表示,而图结构可以为模型提供额外的信息,从而提高模型的性能。
半监督学习在许多领域都有应用,例如:
- 自然语言处理:例如,文本分类、情感分析、机器翻译等。
- 计算机视觉:例如,图像分类、目标检测、图像分割等。
- 推荐系统:例如,推荐电影、音乐、商品等。
半监督学习是一个活跃的研究领域,新的算法和应用不断涌现。随着研究的深入,半监督学习将在机器学习中发挥越来越重要的作用。
DALL·E 2
两阶段模型 prior 和 decoder
- prior :text embedding => image embedding
- decoder:image embedding => 图像
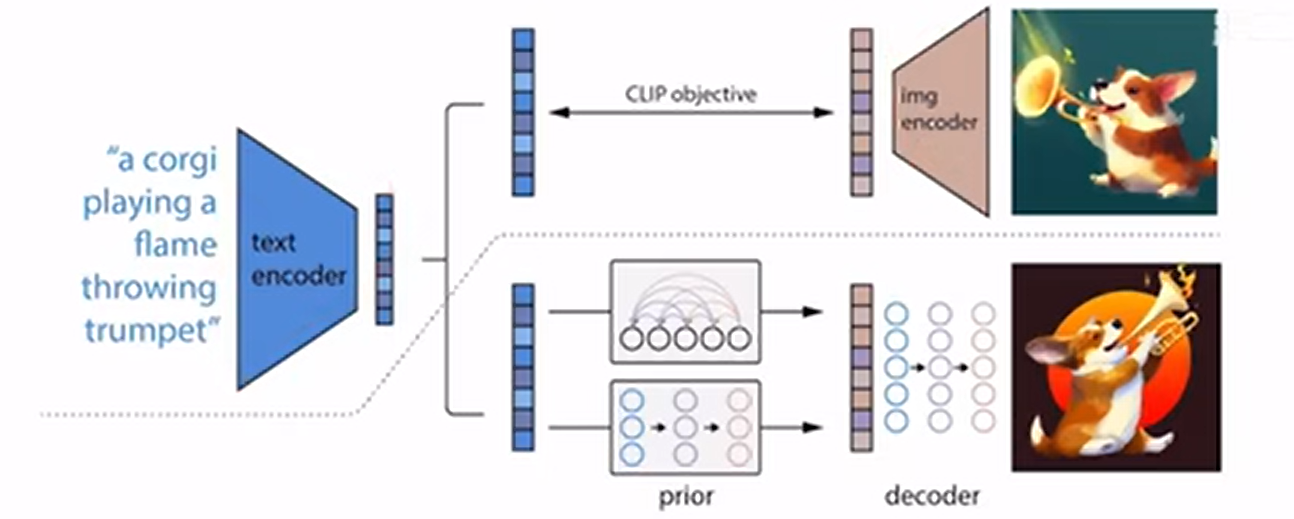
CLIP:输入文本对和图像对进行对比学习,这个对是正样本,其他都是负样本
扩散模型:扩散模型 (Diffusion Model) 之最全详解图解-CSDN博客
自监督学习,在原图像的基础上逐步加入噪声,然后再逐步重建(马尔科夫链)